How to troubleshoot RHEL performance bottlenecks
This tip provides a step-by-step approach to application-tuning, troubleshooting bottlenecks and enhancing performance on RHEL 5 systems.
You've just had your first cup of coffee and have received that dreaded phone call. The system is slow. What are you going to do? This article will discuss performance bottlenecks and optimization in Red Hat Enterprise Linux (RHEL5).
Before getting into any monitoring or tuning specifics, you should always use some kind of tuning methodology. This is one which I've used successfully through the years:
1. Baseline – The first thing you must do is establish a baseline, which is a snapshot of how the system appears when it's performing well. This baseline should not only compile data, but also document your system's configuration (RAM, CPU and I/O). This is necessary because you need to know what a well-performing system looks like prior to fixing it.
2. Stress testing and monitoring – This is the part where you monitor and stress your systems at peak workloads. It's the monitoring which is key here – as you cannot effectively tune anything without some historic trending data.
3. Bottleneck identification – This is where you come up with the diagnosis for what is ailing your system. The primary objective of section 2 is to determine the bottleneck. I like to use several monitoring tools here. This allows me to cross-reference my data for accuracy.
4. Tune – Only after you've identified the bottleneck can you tune it.
5. Repeat – Once you've tuned it, you can start the cycle again – but this time start from step 2 (monitoring) – as you already have your baseline.
It's important to note that you should only make one change at a time. Otherwise, you'll never know exactly what impacted any changes which might have occurred. It is only by repeating your tests and consistently monitoring your systems that you can determine if your tuning is making an impact.
RHEL monitoring tools
Before we can begin to improve the performance of our system, we need to use the monitoring tools available to us to baseline. Here are some monitoring tools you should consider using:
Oprofile
This tool (made available in RHEL5) utilizes the processor to retrieve kernel system information about system executables. It allows one to collect samples of performance data every time a counter detects an interrupt. I like the tool also because it carries little overhead – which is very important because you don't want monitoring tools to be causing system bottlenecks. One important limitation is that the tool is very much geared towards finding problems with CPU limited processes. It does not identify processes which are sleeping or waiting on I/O.
The steps used to start up Oprofile include setting up the profiler, starting it and then dumping the data.
First we'll set up the profile. This option assumes that one wants to monitor the kernel.
# opcontrol --setup –vmlinux=/usr/lib/debug/lib/modules/'uname -r'/vmlinux
Then we can start it up.
# opcontrol --start
Finally, we'll dump the data.
# opcontrol --stop/--shutdown/--dump
SystemTap
This tool (introduced in RHEL5) collects data by analyzing the running kernel. It really helps one come up with a correct diagnosis of a performance problem and is tailor-made for developers. SystemTap eliminates the need for the developer to go through the recompile and reinstallation process to collect data.
Frysk
This is another tool which was introduced by Red Hat in RHEL5. What does it do for you? It allows both developers and system administrators to monitor running processes and threads. Frysk differs from Oprofile in that it uses 100% reliable information (similar to SystemTap) - not just a sampling of data. It also runs in user mode and does not require kernel modules or elevated privileges. Allowing one to stop or start running threads or processes is also a very useful feature.
Some more general Linux tools include top and vmstat. While these are considered more basic, often I find them much more useful than more complex tools. Certainly they are easier to use and can help provide information in a much quicker fashion.
Top provides a quick snapshot of what is going on in your system – in a friendly character-based display. 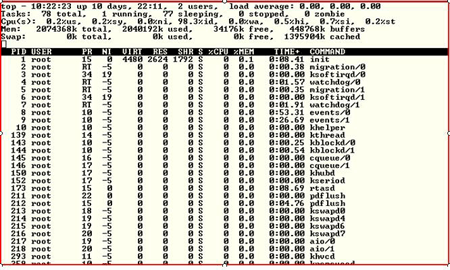
It also provides information on CPU, Memory and Swap Space.
Let's look at vmstat – one of the oldest but more important Unix/Linux tools ever created. Vmstat allows one to get a valuable snapshot of process, memory, sway I/O and overall CPU utilization.

Now let's define some of the fields:
Memory
swpd – The amount of virtual memory
free – The amount of free memory
buff – Amount of memory used for buffers
cache – Amount of memory used as page cache
Process
r – number of run-able processes
b – number or processes sleeping. Make sure this number does not exceed the amount of run-able processes, because when this condition occurs it usually signifies that there are performance problems.
Swap
si – the amount of memory swapped in from disk
so – the amount of memory swapped out.
This is another important field you should be monitoring – if you are swapping out data, you will likely be having performance problems with virtual memory.
CPU
us – The % of time spent in user-level code.
It is preferable for you to have processes which spend more time in user code rather than system code. Time spent in system level code usually means that the process is tied up in the kernel rather than processing real data.
sy – the time spent in system level code
id – the amount of time the CPU is idle wa – The amount of time the system is spending waiting for I/O.If your system is waiting on I/O – everything tends to come to a halt. I start to get worried when this is > 10. There is also: Free – This tool provides memory information, giving you data around the total amount of free and used physical and swap memory.

Now that we've analyzed our systems – lets look at what we can do to optimize and tune our systems.
CPU Overhead – Shutting Running Processes
Linux starts up all sorts of processes which are usually not required. This includes processes such as autofs, cups, xfs, nfslock and sendmail. As a general rule, shut down anything that isn't explicitly required. How do you do this? The best method is to use the chkconfig command.
Here's how we can shut these processes down.
[root
-->
-->
-->
-->
-->
-->
-->
_29_140_234 ~]# chkconfig --del xfs
You can also use the GUI - /usr/bin/system-config-services to shut down daemon process.
Tuning the kernel
To tune your kernel for optimal performance, start with:
sysctl – This is the command we use for changing kernel parameters. The parameters themselves are found in /proc/sys/kernel
Let's change some of the parameters. We'll start with the msgmax parameter. This parameter specifies the maximum allowable size of a single message in an IPC message queue. Let's view how it currently looks.
[root@172_29_139_52 ~]# sysctl kernel.msgmax
kernel.msgmax = 65536
[root@172_29_139_52 ~]#
There are three ways to make these kinds of kernel changes. One way is to change this using the echo command.
[root@172_29_139_52 ~]# echo 131072 >/proc/sys/kernel/msgmax
[root@172_29_139_52 ~]# sysctl kernel.msgmax
kernel.msgmax = 131072
[root@172_29_139_52 ~]#
Another parameter that is changed quite frequently is SHMMAX, which is used to define the maximum size (in bytes) for a shared memory segment. In Oracle this should be set large enough for the largest SGA size. Let's look at the default parameter:
# sysctl kernel.shmmax
kernel.shmmax = 268435456
This is in bytes – which translates to 256 MG. Let's change this to 512 MG, using the -w flag.
[root@172_29_139_52 ~]# sysctl -w kernel.shmmax=5368709132
kernel.shmmax = 5368709132
[root@172_29_139_52 ~]#
The final method for making changes is to use a text editor such as vi – directly editing the /etc/sysctl.conf file to manually make our changes.
To allow the parameter to take affect dynamically without a reboot, issue the sysctl command with the -p parameter.
Obviously, there is more to performance tuning and optimization than we can discuss in the context of this small article – entire books have been written on Linux performance tuning. For those of you first getting your hands dirty with tuning, I suggest you tread lightly and spend time working on development, test and/or sandbox environments prior to deploying any changes into production. Ensure that you monitor the effects of any changes that you make immediately; it's imperative to know the effect of your change. Be prepared for the possibility that fixing your bottleneck has created another one. This is actually not a bad thing in itself, as long as your overall performance has improved and you understand fully what is happening.
Performance monitoring and tuning is a dynamic process which does not stop after you have fixed a problem. All you've done is established a new baseline. Don't rest on your laurels, and understand that performance monitoring must be a routine part of your role as a systems administrator.
About the author: Ken Milberg is a systems consultant with two decades of experience working with Unix and Linux systems. He is a SearchEnterpriseLinux.com Ask the Experts advisor and columnist.







