high availability (HA)
What is high availability (HA)?
High availability (HA) is the ability of a system to operate continuously for a designated period of time even if components within the system fail. A highly available system meets an agreed-upon operational performance level by eliminating single points of failure. This is accomplished by including redundant components that serve as backups that can assume processing if failure should occur. In information technology (IT), a widely held but difficult-to-achieve standard of availability is known as five-nines availability, which means the system or product is available 99.999% of the time.
HA systems are used in situations and industries where it is critical that the system remains operational. Real-world HA systems include those needed for military controls, autonomous vehicles, industrial operations, telecommunication networks and healthcare systems. People's lives might depend on these systems being available and functioning at all times. For example, if the system operating an autonomous vehicle, such as a self-driving car, fails to function when the vehicle is in operation, it could cause an accident, endangering its passengers, other drivers and vehicles, pedestrians and property.
Highly available systems must be well-designed and thoroughly tested before they're implemented in a production environment. The components in an HA system must be able to maintain the specified availability standard in the event of service disruptions. Data backup and failover capabilities play important roles in ensuring HA systems meet their availability goals, as do data storage and access technologies.
How does high availability work?
It is impossible for systems to be available 100% of the time. Organizations that require the highest possible availability generally strive for five nines as the standard of operational performance. However, not all workloads require such rigid standards, so some organizations settle on only three-nines (99.9%) or four-nines (99.99%) availability.
Regardless of their availability goals, IT teams generally adhere to the following principles when designing their HA systems:
- Eliminate any single points of failure. A single point of failure is a component that would cause the whole system to fail if that component fails. For example, if a business uses only one server to run an application, that server represents a single point of failure. Should the server fail, the application will be unavailable.
- Build in reliable failover. If a system component fails, a similar component must be immediately available to take over for the failed component. For this reason, the system must include redundant components and ensure reliable failover, which is the process of switching from one component to another without losing data or affecting performance or operations.
- Implement automatic failure detection. Failures or faults must be immediately detected and acted upon. Ideally, the system will have built-in automation to handle the failure on its own. It should also have built-in mechanisms for avoiding common-cause failures, where two or more systems or components fail simultaneously, likely from the same cause.
- Ensure no data loss. When a component fails, it is possible for data to be lost if data protections have not been put into place. An HA system should include the mechanisms necessary to avoid or minimize data loss during system failure.
Many HA systems also incorporate load balancing into their operations, especially when supporting a high rate of concurrent users. Load balancing automatically distributes workloads among system resources, such as sending incoming requests to different servers. The load balancer decides which system resource is most capable of efficiently handling each workload request. The use of multiple load balancers ensures that no single resource is overwhelmed, eliminating any single points of failure.
The servers in an HA system are set up in clusters and organized in a tiered architecture to respond to requests from load balancers. If one server in a cluster fails, another server can take over the workload, with minimal impact on performance or service delivery. This sort of redundancy enables failover to a secondary component, which takes over the workload when the first component fails.
The more complex a system is, the more difficult it is to ensure high availability because there are more points of failure in a complex system.
Why is high availability important?
Systems that must be up and running most of the time are often the ones that affect people's health, economic well-being, or access to food, shelter and other fundamentals of life. In other words, they are systems that will have a severe impact on a business or people's lives if they fall below a certain level of operational performance.
As mentioned earlier, autonomous vehicles are clear candidates for HA systems. For example, if a self-driving car's front-facing sensor malfunctions and mistakes the side of a tractor-trailer for the road, the car will crash. Although the car was functional, the failure of one of its components to meet the necessary level of operational performance resulted in what would likely be a serious accident.
Electronic health records (EHRs) are another example where lives depend on HA systems. When a patient shows up in the emergency room in severe pain, the doctor needs instant access to the patient's medical records to get a full picture of the patient's history and make the best treatment decisions. Is the patient a smoker? Is there a family history of heart complications? What other medications is the patient taking? Answers to these questions are needed immediately and can't be subject to delays due to system downtime.
How availability is measured
Availability can be measured relative to a system being 100% operational or never failing -- meaning it has no outages. For example, you can calculate the monthly availability rate based on the number of minutes in the month and the number of minutes of downtime during that month, as shown in the following formula:
Availability = (minutes in month - minutes of downtime) * 100/minutes in month
For example, the number of minutes for a 30-day month is 43,200. If the downtime is 10 minutes, you can use the following equation to calculate the availability rate:
Availability = (43,200 - 10) * 100/43,200 = 43,190 * 100/43,200 = 4,319,000/43,200 = 99.976852
This comes to an availability rate of about 99.98%. In comparison, the amount of downtime for the same month at an availability rate of 99.99% (four nines) would be only 4.32 minutes.
IT teams also use other metrics to measure the availability of their systems:
- Mean time between failures. MTBF is the expected time between two failures for the given system.
- Mean downtime. MDT is the average time that a system is nonoperational.
- Recovery time objective. RTO is the total time a planned outage or recovery from an unplanned outage will take. RTO is also referred to as estimated time of repair.
- Recovery point objective. RPO is the maximum amount of data loss that an organization can tolerate if failure occurs.
IT teams can use these metrics as guidelines when planning the levels of availability they're trying to achieve in their systems. Service providers can also use these metrics when guaranteeing a certain level of service to their customers, as stipulated in their service-level agreements (SLAs). An SLA is a contract that outlines the type and level of services to be provided, including the level of availability.

Availability metrics are subject to interpretation as to what constitutes the availability of the system or service to the end user. Even if systems continue to partially function, users might deem them unusable based on performance problems.
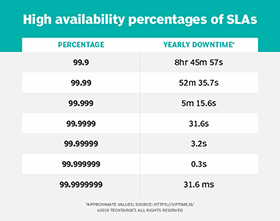
Despite this level of subjectivity, availability metrics should still be concretely defined in the SLAs that service providers offer their customers. For example, if an SLA promises 99.999% availability (five nines), customers can expect the service to be unavailable for the following amounts of time:
| Time period | Time system is unavailable |
| Daily | 0.9 seconds |
| Weekly | 6.0 seconds |
| Monthly | 26.3 seconds |
| Yearly | 5 minutes and 15.6 seconds |
To provide context, if a company adheres to the three-nines standard (99.9%), there will be about 8 hours and 45 minutes of system downtime in a year. Downtime with a two-nines standard (99%) is even more dramatic, equating to a little over three days of downtime a year. Cloud service providers generally promise at least 99.9% availability for their paid services, although they've more recently moved to 99.99% availability for some services.
How to achieve high availability
Organizations take different approaches to ensuring that their systems are highly available. The following six steps describe a common approach for achieving high availability:
- Design the system with HA in mind. The goal of designing an HA system is to create one that meets performance and availability requirements, while minimizing cost and complexity. Single points of failure should be eliminated with redundancy. IT teams should be specific about the levels of availability they are trying to achieve and which metrics will be used to measure that availability. Service providers might also use this information in their SLAs.
- Deploy the hardware. Hardware should be resilient and performant, while balancing quality with cost-effectiveness. Hot-swappable and hot-pluggable hardware is particularly useful in HA systems because the equipment doesn't have to be powered down when swapped out or when components are plugged in or unplugged.
- Test the failover process. Once the system is up and running, the failover process should be checked to ensure that workloads can be switched over to the backup component in case of failure. Applications should be tested and retested as time goes on, with a testing schedule put in place.
- Monitor the system. The system's performance and operations should be tracked using metrics and observation. Any variance from the norm must be logged and evaluated to determine how the system was affected and what adjustments are required.
- Evaluate. The data gathered from monitoring should be analyzed to find ways to improve the system. This process should be ongoing to ensure availability as conditions change and the system evolves.
High availability and disaster recovery
Disaster recovery (DR) is the process of restoring systems and services after a catastrophic event, such as a natural disaster that destroys the physical data center or other infrastructure. Organizations commonly implement DR strategies so they can be prepared to handle such events and be back up and running with minimal disruption to their operations. HA strategies, on the other hand, deal with smaller, more localized failures or faults than the types targeted by DR plans.
Despite the differences between DR and HA, they both strive to ensure business continuity in the event of system disruptions, and they both use redundancy to minimize those disruptions if they do occur. Redundant components make it possible to failover workloads should the active components fail. Redundancy can apply to servers, storage systems, network nodes, satellite facilities or entire data centers. For example, if a database server fails, an organization should be able to switch to a backup server with little disruption to service.
Both DR and HA also make use of data backups to ensure there is always at least one or more good copies of the data no matter what type of event might occur. Data backups help to maintain availability in the case of data loss, corruption or storage failures. An organization should be able to quickly restore data from its backups, with little to no loss of data.
High availability and fault tolerance
Like DR, fault tolerance helps ensure a system's availability if an event disrupts operations. Fault tolerance refers to a system's ability to continue to operate if one or more components fail, even if several failures occur simultaneously.
While HA attempts to meet a specific availability goal, fault tolerance strives for zero downtime. To this end, a fault-tolerant system requires redundancy throughout the entire infrastructure and application stack. Unlike HA, fault tolerance isn't concerned with achieving a minimal level of performance, only to keep operating in the event of hardware failure.
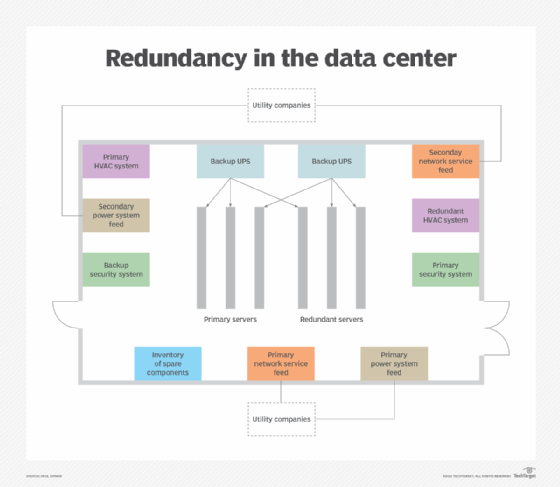
To achieve the level of redundancy in the data center that fault tolerance requires, IT teams typically follow an N+1, N+2, 2N or 2N+1 strategy, where N represents the number of components needed to keep the system running. For example, if the components are servers, the strategies can be applied as follows:
- N+1 model. The design starts with the number of servers needed to support the target workloads and then adds one more server.
- N+2 model. The design starts with the number of servers needed to support the target workloads and then adds two more servers.
- 2N model. The design includes twice as many servers as the number needed to support the target workloads.
- 2N + 1 model. The design starts with twice as many servers as the number needed to support the target workloads and then adds one more server.
By applying these strategies to infrastructure that supports mission-critical workloads, IT always has at least one backup of each essential component so there is little disruption in service if a failure occurs.
It is possible for a system to be highly available but not fault-tolerant. For example, an HA cluster might host a virtual machine on one of its servers. If the VM becomes unavailable for any reason, the hypervisor might try to restart the VM in the same cluster, which likely will be successful if the problem is software-based.
However, if the problem is related to the cluster's hardware and the system is not fault-tolerant, restarting the VM in the same cluster might not fix the problem. A fault-tolerant system would ensure that another cluster could take over the operation, and the VM would restart on that cluster. A DR strategy would go a step further by ensuring that there is a copy of the entire system somewhere else for use in the event of a large catastrophe.
High availability best practices
A highly available system should be able to quickly recover from any sort of failure, while minimizing service disruptions for the end user. When implementing HA systems, IT teams often adopt some form of the following best practices:
- Eliminate single points of failure for any components whose failure would disrupt operations.
- Ensure all essential data is backed up and can be recovered quickly and easily.
- Use load balancing to distribute application and network traffic across servers and other hardware. An example of a load balancer is HAProxy.
- Continuously monitor the health and performance of back-end database servers.
- Distribute resources in different geographical regions in case one region should experience power outages or natural disasters.
- Implement reliable failover that takes into account the storage systems, using technologies such as redundant array of independent disks (RAID) or a storage area network (SAN).
- Set up a system for detecting and responding to failures as soon as they occur.
- Design system components for high availability and test their functionality before implementation.
Find out the questions to ask about cloud applications to determine the level of availability they need and whether all that availability is necessary.






