grid computing
What is grid computing?
Grid computing is a system for connecting a large number of computer nodes into a distributed architecture that delivers the compute resources necessary to solve complex problems.
The nodes can include servers or personal computers that are loosely linked together by the internet or other networks and, in many cases, distributed across multiple geographic regions. Grid computing uses the resources available to each node to run independent tasks that contribute to the larger endeavor.
Grid computing provides an architecture for creating a virtual supercomputer made up of distributed computer nodes. Most grid computing projects have no time dependency, and large projects are typically deployed across many countries and continents. In many cases, a grid computing system will leverage a node's idle resources to perform grid-related tasks, a process known as cycle-scavenging or CPU-scavenging. These tasks might run in the background for many weeks, if not longer.

Each node runs specialized grid computing software that enables participation in the grid. A grid environment also requires a control node -- typically a server -- to handle administrative operations and schedule tasks. In addition, a grid environment uses middleware to create and control the grid, as well as manage processes across the nodes and enable communications between application components.
One example of middleware is Berkley Open Infrastructure for Network Computing (BOINC), an open source grid computing platform used extensively in scientific research. Projects can build on tools such as BOINC by adding user-friendly GUIs, as well as functionality for distributing raw data and receiving and storing results.
In a grid computing environment, it's highly probable that multiple compute nodes will disconnect or fail. For this reason, an organization should build redundancy and robust failure recovery into the model.
The organization should also consider security considerations and the need for quality control. In some grid environments, for example, the controls are very loose, and it's easy to set up a grid project or join an existing one. If security or quality are top priorities, the organization must ensure that the proper controls have been implemented to protect their resources.
How does grid computing differ from other environments?
Grid computing is sometimes referred to as virtual supercomputing, but grid computing differs from supercomputing in several important ways. A supercomputer is made up of a massive set of processors that run in parallel in a confined area, such as a specialized data center. A grid environment can be -- and often is -- distributed across the globe.
Supercomputers also use high-speed networks and run highly connected applications, rather than independently functional nodes. Grid systems, on the other hand, exchange little or no data between nodes and typically communicate over internet connections from geographically dispersed locations.
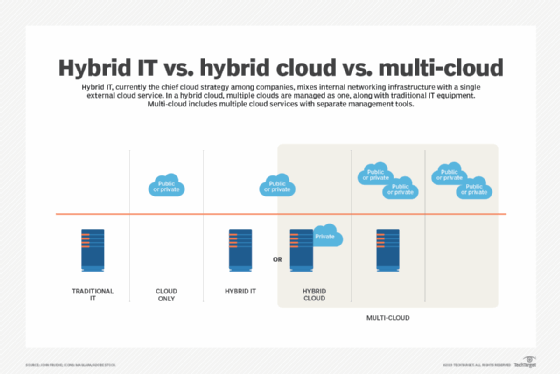
Grid computing also differs from cloud computing, another form of distributed computing. Cloud computing falls somewhere between grid computing and supercomputing.
Cloud environments are much more granular than grid environments and can handle time-dependent workloads more effectively. Although cloud resources can be geographically distributed, they tend to be limited to only a few locations, as compared to the thousands or millions of widely distributed nodes that participate in a grid network.
Grid computing is often seen as a predecessor to cloud computing, which has come to play a prominent role in world-wide computing. In fact, cloud computing could pose a threat to grid computing over the long-term. The centralization of servers in the cloud leaves fewer idle cycles to scavenge from on-premises servers, while reducing the number of underutilized desktops.
However, it's possible to use the cloud to support grid-based applications, either entirely or in a hybrid configuration. In this way, organizations can take advantage of some of the benefits that come with the cloud, such as elastic scaling and the pay-as-you-go service model, while still taking advantage of the grid model. This approach could prove beneficial to organizations already investing resources in supporting grid nodes.
What are the uses of grid computing?
Grid computing has been used by governments, universities, commercial enterprises and a variety of other organizations and individuals to collaborate on projects and solve problems. Grid systems can deliver computing power to a wide range of projects, including genetic research, drug-candidate matching, government safety programs and historical investigations, such as searching for Genghis Khan's tomb.
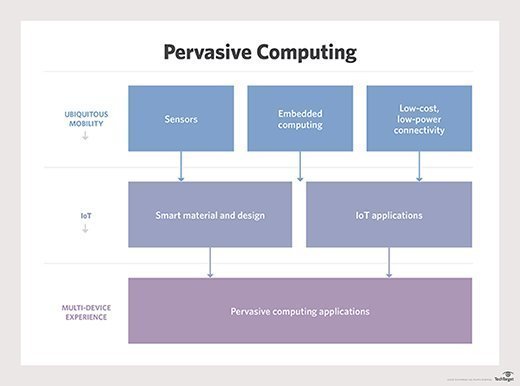
Grid computing can also be used for a variety of other types of analytics, such as modeling financial risks, studying seismic activity or analyzing weather patterns. In addition, grid computing can play a role in pervasive computing, where intelligent devices pervade an environment without the user's direct awareness.
One popular grid project has been SETI@home, a scientific experiment based at the University of California at Berkeley. The project has been using internet-connected computers to search for extraterrestrial intelligence, with millions of PCs running a search program against a segmented piece of radio telescope data. Although the SETI@home project is no longer distributing tasks, the project continues to work on the back-end data analysis.
The grid computing architecture can bring massive processing power to bear on a problem, as SETI@home and similar projects have shown. However, the distributed model works well for only a narrow subset of applications.
See also hardware as a service, utility computing, Open Grid Services Architecture, provisioning, computer-intensive and chaos engineering.






