Safer failover testing procedures for the data center
Haphazard failover testing can be dangerous, but you can minimize the potential risk of data loss or corruption by following a few straightforward procedures.

Some data center pros have unorthodox ways of checking fault tolerance. For example, I asked a friend who is a network administrator for a medium-sized organization about his failover testing procedures. He said that at random times, he walks through the data center and yanks a power cord out of the back of a random server or switch. That way, he not only tests the resiliency of the failover infrastructure but also his staff’s ability to notice that a failover has occurred and to fix the problem.
Even though this method seems to work for my friend, disconnecting random power cords is probably not the best failover testing method in a production environment. Although that technique might allow you to find out how well your fault-tolerant solutions work, it also poses a tremendous amount of risk because it will result in an outage unless all fault-tolerant mechanisms are working perfectly.
Another problem with yanking a power cord out of a cluster node is that it simulates only one type of failure. A better approach is to design a series of tests that check your system’s ability to handle various types of failures. This failover testing can be arranged so that the least risky tests are performed . That way, if you do happen to find a problem during some of the earlier tests, you can correct it before you get to any of the riskier tests.
What are the risks?
Before you can design a series of tests to minimize the risks associated with the testing process, you have to understand what the risks are.
Normally, if you are testing your failover systems and something goes wrong, you can just put things back to the way they were before the tests and be back online in a matter of minutes.
But things don’t always work that way. A few years ago, I was asked to supervise a data center move in case anything went wrong. The move was supposed to be an easy one. Servers were simply being moved from one part of the building to another. The was to move one node from each cluster to the location.
After the move, the was to power up those nodes. Once all of the cluster nodes were back up, the second cluster node would be taken offline and moved to the location. The process was to be repeated until all servers had been moved.
At everything was going according to . Then one of the servers refused to power up after being moved. There were no visible signs of damage, and yet the server showed no signs of life. Against all odds, the server’s power supply had burned out as the server was shut down. The organization didn’t suffer any downtime because other cluster nodes were still functional, but this situation underscores the point that unexpected failures can — and sometimes do — occur when servers are taken offline.
Another risk associated with failover testing is data loss or data corruption. Take Microsoft Exchange Server, for instance. When messages are sent or received, the transaction is written to and then to a transaction log file. The transaction log is eventually written to the mailbox database.
If a failure occurs before a transaction can be written to a transaction log file, then that data is lost. Similarly, clustered mailbox servers use a log shipping mechanism to copy transaction logs to passive cluster nodes. Transaction logs are not shipped until they accumulate 1 MB of data in Microsoft Exchange Server 2007. Because of that, the active cluster node always has at least some data that has not been replicated to the passive node. Depending on the nature of the failover and on the actions taken after the failover has occurred, there is potential for the nonreplicated data to be lost.
Start with a visual inspection
To find out how fault-tolerant your cluster nodes really are, the safest way to start is by performing a visual inspection. The trick is to look for any hardware that could become a single point of failure.
Here’s a perfect example I witnessed a few years ago: A small organization had created a failover cluster to achieve hardware redundancy. But rather than purchase a separate uninterrupted power supply for each cluster node, someone had plugged a power strip into the existing UPS’s only remaining outlet and then plugged both cluster nodes into that power strip. One day the power went out, and everything that was connected to the overloaded UPS instantly failed. The UPS had become a single point of failure.
Single points of failure are not always that dramatic. Consider the example of an organization that installed redundant Ethernet switches so that a switch failure would not cause an outage. One server’s two NICs had accidentally been connected to the same switch. It was a small accident that was easily corrected, but the mistake could have undermined the IT staff’s efforts to make the network fault tolerant.
Perform a manual failover
After you have completed a visual inspection, you have to test to find out if your cluster nodes fail over in the way they were designed. Begin by performing a manual failover.
Most clustering software contains a mechanism for failing over cluster nodes without actually having to shut down any server hardware. For example, in Windows Server 2008 , you can open the Failover Cluster Management Console, right-click on the clustered application, and then choose the Move This Service or Application to Another Node command from the shortcut menu. You can see what this looks like in Figure 1.
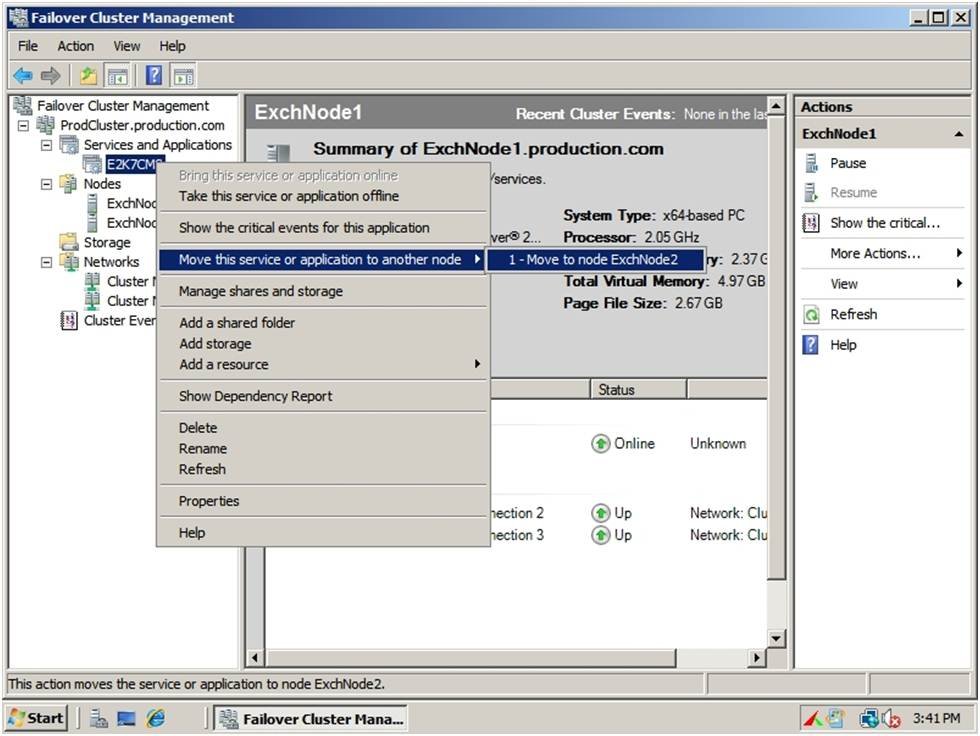
Shut down a cluster node
As you progress through your testing regiment, eventually you’ll want to verify that the cluster can continue to function even with a cluster node offline. When you get to that point, gracefully shut down the node on which you want to simulate a failure.
A graceful shutdown isn’t as dramatic as yanking out the power cord, but pulling the power cord can be hard on the server hardware. Abruptly cutting the power has the potential to cause corruption on the cluster node’s system drive. It may also reduce the lifespan of the server’s system board or power supply.
Test at the switch, not at the server
One of the safest ways to conduct failover testing is to disconnect the Ethernet cables from a server’s network interface card (NIC). A cluster node in a virtual data center typically has at least three NICs. One is used for normal network communications. A second NIC handles heartbeat traffic between cluster nodes, while the third connects the server to a shared storage pool. Of course there may be many more NICs present for the sake or redundancy or load balancing.
In any case, you can simulate different types of failures by disconnecting the various network cables. For example, if you want to trigger a failover, you can disconnect the cable used for heartbeat traffic.
Scheduling failover testing
Even though many organizations are 24-hour-a-day operations, don’t let that stop you from failover testing if you possibly can. There are several advantages of scheduled testing.
For starters, when everyone is warned ahead of time that you’ll be performing failover tests, then if the failover mechanisms fail during the tests, the repercussions shouldn’t be severe.
Another advantage to performing scheduled testing is that doing so may give you the opportunity to hedge your bets a bit. Suppose for instance that you on testing the failover capabilities of a cluster that is hosting some virtualized SQL Servers. Before the test begin, you could take the SQL databases offline as a way of helping to prevent any data corruption from occurring if the testing goes badly.
In this type of situation, taking the SQL databases offline ahead of time wouldn’t affect the reliability of your tests because if you are only testing your ability to fail over a virtual server, then the applications running on the server are irrelevant to the test. Therefore, there is no reason why you can’t take some steps to protect your data before attempting a failover.
About the author: Brien M. Posey has received Microsoft’s Most Valuable Professional award seven times for his work with Windows Server, IIS, file systems/storage and Exchange Server. He has served as CIO for a nationwide chain of hospitals and healthcare facilities and was once a network administrator for Fort Knox.






