Data center management for geographically split data centers
Geographically split data centers can reduce disaster recovery time to zero, but splitting data centers requires an intelligent network and savvy data center management.

Business and regulatory requirements constantly push the limits of data center management and recovery. Twenty years ago, trucking tapes to a remote center for volume restores was good enough. Ten years ago, two data centers within synchronous I/O distance fit the bill. Now, with e-commerce being the primary workload driver, a good recovery plan involves data centers split over geographic distances with little or no recovery time.
The geographically split concept and data center management
Conceptually, the geographically split idea starts with two data centers, as shown below (Figure 1). Note that this concept may be extended to any number of sites.
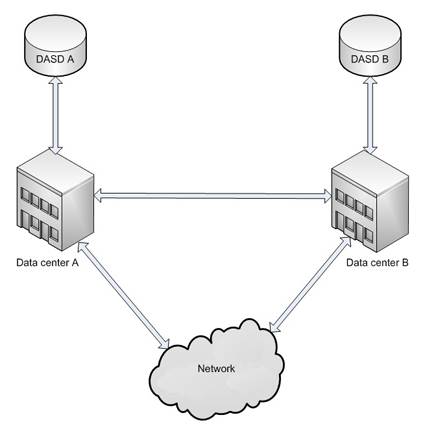
Figure 1: Diagram of geographically split data centers.
In Figure 1, two data centers are separated by a distance too great for synchronous disk I/O. The distance drives several requirements. First, each data center must have its own Direct Access Storage Device (DASD) farm to manage. Second, synchronous hardware replication will not work because of network latency. Lastly, the distance also means the logical partitions (LPARs) in each data center can’t be in the same Sysplex.
The network cloud bears an important role in data center management and as a switch between the two data centers. With proper internal plumbing, incoming requests can be routed to either data center site based on diverse criteria. In fact, with today’s browser-based applications, a user or customer may be switched between the data centers without interruption.
Because hardware replication is unavailable, data must be captured and applied at the logical database or access method level. There are several products available to help with this task. Some products look for updates by reading database or Virtual Storage Access Method (VSAM) logs for updates. Any interesting changes are hurled to the other data center via communication links using various transport protocols. At the receiving end, another piece of software issues the database or access method command to complete the remote update.
Configurations for geographically split data centers
Split data centers may be configured in several ways. The ones that come to mind are:
Hot-warm
In the enterprise, one data center is designated as the target of all network traffic. Updates in the primary data center are replicated to the secondary site, which receives and applies the changes to its local DASD farm. In the event of a primary data center failure, the secondary site comes online with minimum fuss.
Update-inquiry
In the update-inquiry scenario, one data center fields all updates while the other only allows inquiries. The update site sends changes to the read-only Sysplex in a timely fashion. If the update data center fails, the inquiry Sysplex assumes full responsibilities.
The network is crucial to this setup as it must be able to query message content to distinguish between inquiry and update transactions. The shop may also use the network for workload balancing so that each data center carries its share of the read-only traffic.
Update-update
This is the real deal. Each data center supports full updates to all data. Two-way replication flows over the communication links to keep the databases in synch. In the event of failure, the surviving data center takes on all incoming traffic.
Note that while both data centers do updates, data may be logically split. For example, the primary databases for customers living west of the Mississippi may be in "Data center A" with secondary, read-only data at "Data center B." Customers residing elsewhere would be the reverse. Ultimately, this means the network must be smart enough to know where a customer’s primary data resides.
Philosophical questions
You more thoughtful readers probably already have the willies thinking about this. Here’s some more food to add to your discomfort:
- Batch -- In update-update mode, batch becomes problematic. An enterprise has to decide which side runs batch, or if batch should be run in both sites. There may also be some concerns with the bandwidth needed to shove updates from I/O bound batch jobs through the replication links.
- Replication Delays -- Modern communication links are fast and reliable, but can still fail. Also note that the fastest, most perfect communication line won’t be nearly as quick and synchronous as DASD I/O. Therefore, the system infrastructure, and to some extent the applications, must be prepared to deal with delays and "stale" data.
- Collisions -- Database Management Systems (DBMS) in different Sysplex’s can’t lock database records across wide distances. This leads to situations where the same database record may be updated at the same time in different data centers. Again, the infrastructure and applications need to be prepared to handle the conflicts.
- Change Control -- Infrastructure, application and database design changes must be carefully managed to avoid breaking replication compatibility between partner data centers.
- Drift -- No asynchronous replication technique working at the logical I/O layer is perfect, and enterprises may find themselves with slowing diverging data stores. Fixing the differences will require some sort of periodic reconciliation process.
- Death -- When should a data center be declared dead? The data centers keep in touch through replication traffic and heartbeats. However, a slowdown in replication traffic may just indicate one data center is doing less work. Likewise, a few missing heartbeats may signal a network failure or slowdown instead of data center failure.
Detecting and acting upon perceived failures requires carefully crafted policies, mountains of automation and careful data center management. The good news is that as geographically split data centers become normal, the policy for handling these issues should become more easily transcribed as a set of rules instead of code.
ABOUT THE AUTHOR: For over 25 years, Robert Crawford has worked off and on as a CICS systems programmer. He is experienced in debugging and tuning applications and has written in COBOL, Assembler and C++ using VSAM, DLI and DB2.





