single point of failure (SPOF)
What is a single point of failure (SPOF)?
A single point of failure (SPOF) is a potential risk posed by a flaw in the design, implementation or configuration of a circuit or system. SPOF refers to one fault or malfunction that can cause an entire system to stop operating.
A SPOF in a data center or other IT environment can compromise the availability of workloads or the entire data center, depending on the location and interdependencies involved in the failure.
Examples of single points of failure
Here are two examples of how a SPOF can manifest:
- Single server. Consider a data center where one server runs a single application. The underlying server hardware would present a single point of failure for the application's availability. If the server failed, the application would become unstable or crash. This event would prevent users from accessing the application, and it could possibly result in data loss. The use of server clustering technology can mitigate this situation. It would allow a duplicate copy of the application to run on a second physical server. If the first server failed, the second would take over to preserve access to the application and avoid the SPOF.
- Lone network switch. Another SPOF example is where an array of servers is networked through a single network switch. If the switch failed or simply became disconnected from its power source, all of the servers connected to that switch would become inaccessible from the rest of the network. Here, the switch is a single point of failure. For a large switch, this could render dozens of servers and their workloads inaccessible. Redundant switches and network connections can provide alternative network paths for interconnected servers if the original switch should fail, avoiding the SPOF.
Identifying single points of failure
Many of the potential SPOFs exist in the data center, frequently without the administrators' knowledge. Virtually every single component in a data center can be a point of failure, often because only one primary system is in use. These components include servers, storage, power equipment and environmental management systems.
Loss of an important system, such as a dedicated server that doesn't have a fallback arrangement, can shut down important activities of the organization. The key is to identify potential point of failure risks and mitigate them before they cause a disaster.
Most SPOFs reflect the presence of only one system that has specific responsibilities. Loss of a such a system, especially one that is not fault tolerant, can disrupt data center operations as well as the firm's business.
While some SPOFs are easy to spot, others may take some digging. The following steps are good to take:
- Examine a map of the data center that shows all its components and their locations.
- Physically go through the data center with a flashlight, removing floor tiles and other plates that cover equipment and cabling.
- Look at network diagrams of the data center and other parts of the building.
- Examine external cables -- such as for power supplies and communications -- and their entry points.
- Make sure the technical diagrams, themselves, are up to date; they can also be a single point of failure.
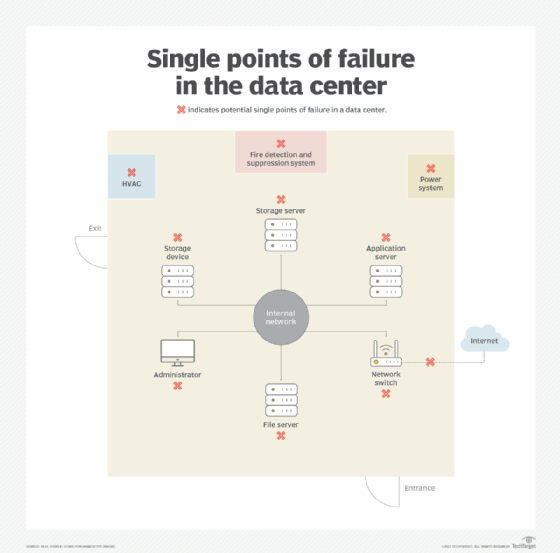
Avoiding single points of failure
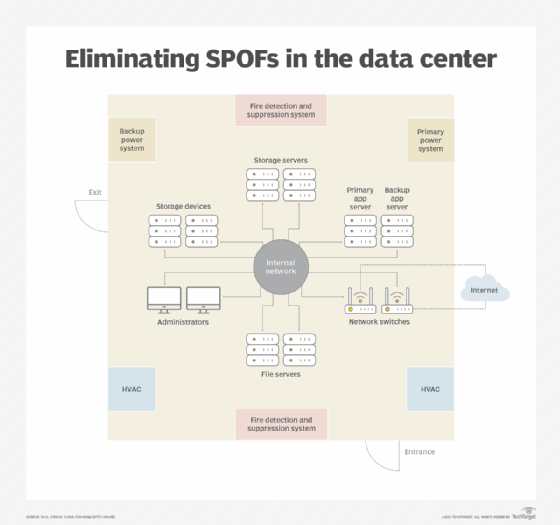
It is the responsibility of the data center architect to identify and correct single points of failure that appear in the infrastructure's design. However, resiliency comes at a cost -- for instance, the price of additional servers within a cluster and additional switches, network interfaces and cabling. Architects must weigh the need for each workload against the cost to avoid each SPOF.
Here, a risk management strategy can help with decision-making.

Single points of failure determined to be worth the cost of preventing can be mitigated and even eliminated. Some ways to mitigate failure issues include the following:
- Backup and redundant systems and software components ensure against the loss of a primary system.
- A second channel or conduit for redundant network cabling protects against loss of connections to local carriers and internet service providers.
- Load balancers send requests for service only to servers that are online and in use. As a result, load balancing reduces the threat of SPOFs where multiple servers are in use.
- Backup power and other electrical systems protect against the loss of power and intermittent power fluctuations that can disrupt business operations. For instance, lightning arrestors and electrical grounding reduce the threat of power surges.
- An up-to-date data security infrastructure mitigates the threat from cybersecurity attacks. This includes firewalls that have current database rules and security tools set and patched for the level of software in use.
- People can also be SPOFs. For example, an organization can be vulnerable if one person has all knowledge of a critical system. Cross-training employees is a wise approach.
Find out more about risk management failures and how to prevent them.







